
3D视觉被过度设计?字节Depth Anything 3来了,谢赛宁点赞
3D视觉被过度设计?字节Depth Anything 3来了,谢赛宁点赞机器之心报道 编辑:泽南、杨文 现在,只需要一个简单的、用深度光线表示训练的 Transformer 就行了。 这项研究证明了,如今大多数 3D 视觉研究都存在过度设计的问题。 本周五,AI 社区最热
来自主题: AI技术研报
9015 点击 2025-11-16 11:27
 搜索
搜索
机器之心报道 编辑:泽南、杨文 现在,只需要一个简单的、用深度光线表示训练的 Transformer 就行了。 这项研究证明了,如今大多数 3D 视觉研究都存在过度设计的问题。 本周五,AI 社区最热

在 3D 视觉领域,如何从二维图像快速、精准地恢复三维世界,一直是计算机视觉与计算机图形学最核心的问题之一。从早期的 Structure-from-Motion (SfM) 到 Neural Radiance Fields (NeRF),再到 3D Gaussian Splatting (3DGS),技术的演进让我们离实时、通用的 3D 理解越来越近。
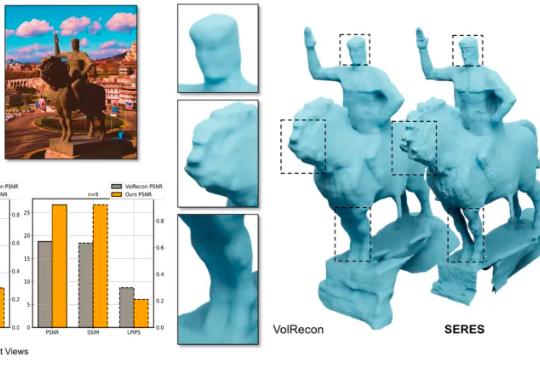
直观经验却告诉我们,只要把同一物体的 “对应部分” 对齐,形状就会变得清晰。基于这一朴素而有效的直觉,作者提出SERES(Semantic-Aware Reconstruction from Sparse Views),在不改动主干框架的前提下,把跨视角的语义一致性变成一种训练期先验注入到模型里,用低成本的方法去解决高价值的歧义问题,让少量视角也能得到清晰而完整的几何。
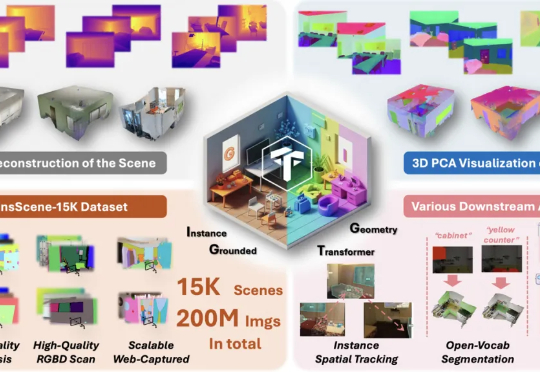
现在,NTU联合StepFun提出了IGGT (Instance-Grounded Geometry Transformer) ,一个创新的端到端大型统一Transformer,首次将空间重建与实例级上下文理解融为一体。

3D点云异常检测对制造、打印等领域至关重要,可传统方法常丢细节、难修复。上海科大与密歇根大学携手打造PASDF框架,借助「姿态对齐+连续表征」技术,达成检测修复一体化,实验显示其精准又稳定。
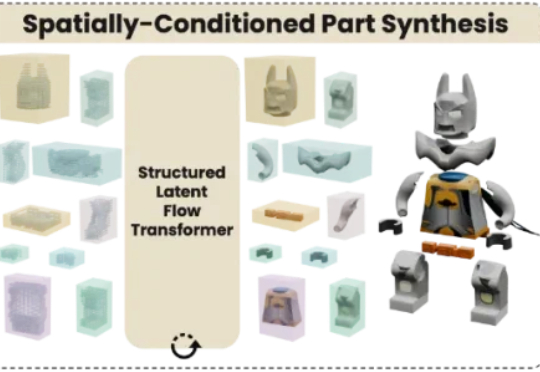
在3D内容创作领域,如何像玩乐高一样,自由生成、编辑和组合对象的各个部件,一直是一个核心挑战。香港大学、VAST、哈尔滨工业大学及浙江大学的研究者们联手,推出了一个名为 OmniPart 的全新框架,巧妙地解决了这一难题。该研究已被计算机图形学顶会 SIGGRAPH Asia 2025 接收。
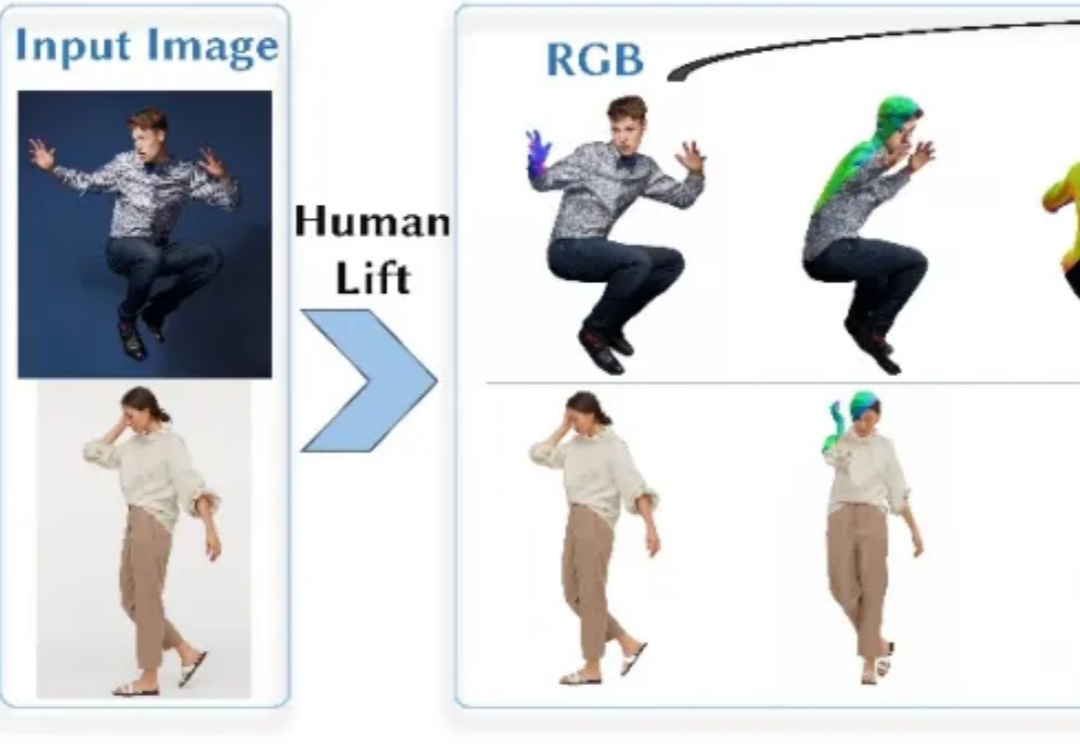
创建具有高度真实感的三维数字人,在三维影视制作、游戏开发以及虚拟/增强现实(VR/AR)等多个领域均有着广泛且重要的应用。

生成式 AI 正在重写 3D 内容的生产流程:从“DCC 工具 + 外包”的线性供给,演进到“资产规模化生成 + 管线可用”的指数供给模式。过去五年,技术范式经历了从实时体积渲染,NeRF,到Score Distillation,3D扩散的快速迭代;需求侧则由游戏与影视,向3D 打印、电商样机、数字人、教育培训、以及AR/VR等长尾场景外溢。
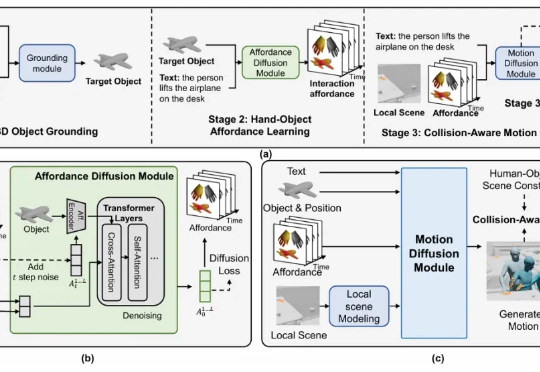
该研究首次提出了含可移动物体的 3D 场景中,基于文本的人 - 物交互生成任务,并构建了大规模数据集与创新方法框架,在多个评测指标上均取得了领先效果。

3D 生成正从纯虚拟走向物理真实,现有的 3D 生成方法主要侧重于几何结构与纹理信息,而忽略了基于物理属性的建模。